FeatureProbe 作为一个开源的『功能』管理服务,包含了灰度放量、AB实验、实时配置变更等针对『功能粒度』的一系列管理操作。需要提供各个语言的 SDK 接入,其中就包括移动端的 iOS 和 Android 的 SDK,那么要怎么解决跨平台 SDK 的问题呢?
一、为什么要跨平台?
- 减少人力成本,减少开发时间。
- 两个平台共享一套代码,后期产品维护简单。
二、目前常见的跨平台方案
很多公司的跨平台移动基础库基本都有 C++ 的影子,如微信,腾讯会议,还有早期的 Dropbox,知名的开源库如微信的 Mars 等。好处是一套代码多端适配,但是需要大公司对 C++ 有强大的工具链支持,还需要花重金聘请 C++ 研发人员,随着团队人员变动,产品维护成本也不可忽视,所以 Dropbox 后期也放弃了使用 C++ 的跨端方案。
Rust 和对应平台的 FFI 封装。常见的方法如飞书和 AppFlow 是通过类似 RPC 的理念,暴露少量的接口,用作数据传输。好处是复杂度可控,缺点是要进行大量的序列化和反序列化,同时代码的表达会受到限制,比如不好表达回调函数。
更适合于有 UI 功能的跨平台完整 APP 解决方案,不适用于跨平台移动端 SDK 的方案。
三、为什么用 Rust ?
不考虑投入成本的话,原生方案在发布、集成和用户 Debug 等方面都会更有优势。但考虑到初创团队配置两个资深的研发人员来维护两套 SDK 需要面临成本问题。
我们之前有用过 Rust 实现过跨平台的网络栈,用 tokio 和 quinn 等高质量的 crate 实现了一个长连接的客户端和服务端。
(1) FeatureProbe 作为灰度发布的功能平台,肩负了降级的职责,对 SDK 的稳定性要求更高。
(2) 原生移动端 SDK 一旦出现多线程崩溃的问题,难以定位和排查,需要较长的修复周期。
(3) Rust 的代码天生是线程安全的,无需依赖于丰富经验的移动端开发人员,也可以保证提供高质量、稳定的 SDK。
四、Uniffi-rs
uniffi-rs 是 Mozilla 出品, 应用在 Firefox mobile browser 上的 Rust 公共组件,uniffi-rs 有以下特点:
安全
简单
- 不需要使用者去学习 FFI 的使用
- 只定义一个 DSL 的接口抽象,框架生成对应平台实现,不用操心跨语言的调用封装。
高质量
- 完善的文档和测试。
- 所有生成的对应语言,都符合风格要求。
五、Uniffi-rs是如何工作的?
首先我们 clone uniffi-rs 的项目到本地, 用喜欢的 IDE 打开 arithmetic 这个项目:
git clone https://github.com/mozilla/uniffi-rs.git
cd examples/arithmetic/src
我们看下这个样例代码具体做了什么:
[Error]
enum ArithmeticError {
"IntegerOverflow",
};
namespace arithmetic {
[Throws=ArithmeticError]
u64 add(u64 a, u64 b);
};
在 arithmetic.udl 中,我们看到定义里一个 Error 类型,还定义了 add, sub, div, equal 四个方法,namespace 的作用是在代码生成时,作为对应语言的包名是必须的。我们接下来看看 lib.rs 中 rust 部分是怎么写的:
#[derive(Debug, thiserror::Error)]
pub enum ArithmeticError {
#[error("Integer overflow on an operation with {a} and {b}")]
IntegerOverflow { a: u64, b: u64 },
}
fn add(a: u64, b: u64) -> Result<u64> {
a.checked_add(b)
.ok_or(ArithmeticError::IntegerOverflow { a, b })
}
type Result<T, E = ArithmeticError> = std::result::Result<T, E>;
uniffi_macros::include_scaffolding!("arithmetic");
下图是一张 uniffi-rs 各个文件示意图,我们一起来看下,上面的 udl 和 lib.rs 属于图中的哪个部分:
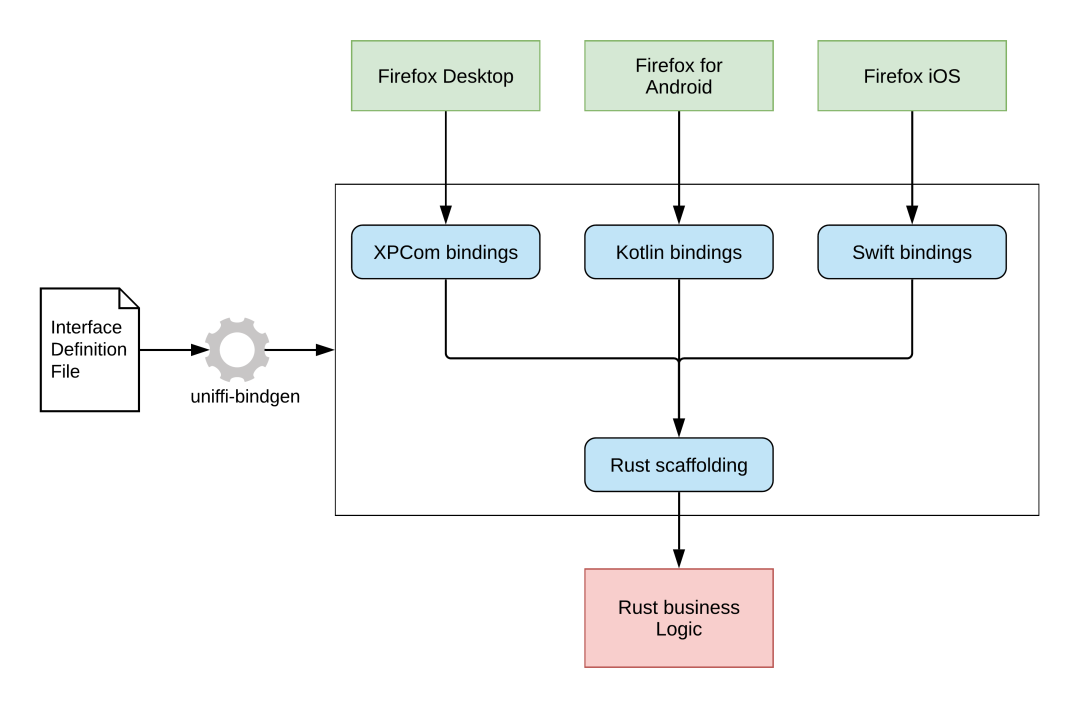 图中最左边 Interface Definition File 对应 arithmetic.udl 文件,图中最下面红色的 Rust Business Logic 对应到 example 中的 lib.rs,test/bindings/ 目录下的各平台的调用文件对应最上面绿色的方块,那方框中蓝色的绑定文件去哪里了呢, 我们发现 lib.rs 最下面有这样一行代码 uniffi_macros::include_scaffolding!("arithmetic"); 这句代码会在编译的时候引入生成的代码做依赖,我们这就执行一下测试用例,看看编译出来的文件是什么:
图中最左边 Interface Definition File 对应 arithmetic.udl 文件,图中最下面红色的 Rust Business Logic 对应到 example 中的 lib.rs,test/bindings/ 目录下的各平台的调用文件对应最上面绿色的方块,那方框中蓝色的绑定文件去哪里了呢, 我们发现 lib.rs 最下面有这样一行代码 uniffi_macros::include_scaffolding!("arithmetic"); 这句代码会在编译的时候引入生成的代码做依赖,我们这就执行一下测试用例,看看编译出来的文件是什么:
如果顺利的话,你会看到:
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
这个测试用例,运行了 python, ruby, swift 和 kotlin 四种语言的调用,需要本地有对应语言的环境,具体如何安装对应环境超出了本文的范围,但是这里给大家一个方法看具体测试用例是如何启动的,我们以 kotlin 为例,在 uniffi-rs/uniffi_bindgen/src/bindings/kotlin/mod.rs 文件中的 run_script 方法里,在 Ok(()) 前面加上一行 println!("{:?}", cmd); 再次运行:
cargo test -- --nocapture
对应平台下的 run_script 方法都可以这样拿到实际执行的命令行内容,接下来我们就能在 uniffi-rs/target/debug 中看到生成的代码:
arithmetic.jar
arithmetic.py
arithmetic.rb
arithmetic.swift
arithmetic.swiftmodule
arithmeticFFI.h
arithmeticFFI.modulemap
其中的 jar 包是 kotlin, py 是 python,rb 是 ruby,剩下4个都是 swift,这些文件是图中上面的平台绑定文件,我们以 swift 的代码为例,看下里面的 add 方法:
public
func add(a: UInt64, b: UInt64)
throws
->
UInt64
{
return try FfiConverterUInt64.lift(
try rustCallWithError(FfiConverterTypeArithmeticError.self) {
arithmetic_77d6_add(
FfiConverterUInt64.lower(a),
FfiConverterUInt64.lower(b), $0)
}
)
}
可以看到实际调用的是 FFI 中的 arithmetic_77d6_add 方法,我们记住这个奇怪名字。目前还缺图中的 Rust scaffolding 文件没找到,它实际藏在 /uniffi-rs/target/debug/build/uniffi-example-arithmetic 开头目录的 out 文件夹中,注意多次编译可能有多个相同前缀的文件夹。我们以 add 方法为例:
// Top level functions, corresponding to UDL `namespace` functions.
#[doc(hidden)]
#[no_mangle]
pub extern "C" fn r#arithmetic_77d6_add(
r#a: u64,
r#b: u64,
call_status: &mut uniffi::RustCallStatus
) -> u64 {
// If the provided function does not match the signature specified in the UDL
// then this attempt to call it will not compile, and will give guidance as to why.
uniffi::deps::log::debug!("arithmetic_77d6_add");
uniffi::call_with_result(call_status, || {
let _retval = r#add(
match<u64 as uniffi::FfiConverter>::try_lift(r#a) {
Ok(val) => val,
Err(err) => return Err(uniffi::lower_anyhow_error_or_panic::<FfiConverterTypeArithmeticError>(err, "a")),
},
match<u64 as uniffi::FfiConverter>::try_lift(r#b) {
Ok(val) => val,
Err(err) => return Err(uniffi::lower_anyhow_error_or_panic::<FfiConverterTypeArithmeticError>(err, "b")),
}).map_err(Into::into).map_err(<FfiConverterTypeArithmeticError as uniffi::FfiConverter>::lower)?;
Ok(<u64 as uniffi::FfiConverter>::lower(_retval))
})
}
其中 extern "C" 就是 Rust 用来生成 C 语言绑定的写法。我们终于知道这个奇怪的 add 方法名是如何生成的了,arithmetic_77d6_add 是 namespace 加上代码哈希和方法名 add 拼接而成。接着看 call_status ,实际是封装了 add 方法实际的返回值, call_with_result 方法定义在 uniffi-rs/uniffi/src/ffi/rustcalls.rs 中,主要是设置了 panichook, 让 Rust 代码发生崩溃时有排查的信息。arithmetic_77d6_add 的核心逻辑是 let _retval = r#add(a, b), 其中的 a,b 在一个 match 语句包裹,里面的 lift 和 lower 主要做的是 Rust 类型和 C 的 FFI 中的类型转换,具体可以看 这里。
到这里,我们就凑齐了上图中的所有部分,明白了 uniffi-rs 的整体流程。
六、如何集成到项目中?
现在,我们知道如何用 uniffi-rs 生成对应平台的代码,并通过命令行可以调用执行,但是我们还不知道如何集成到具体的 Android 或者 Xcode 的项目中。在 uniffi-rs 的帮助文档中,有 Gradle 和 XCode 的集成文档,但是读过之后,还是很难操作。
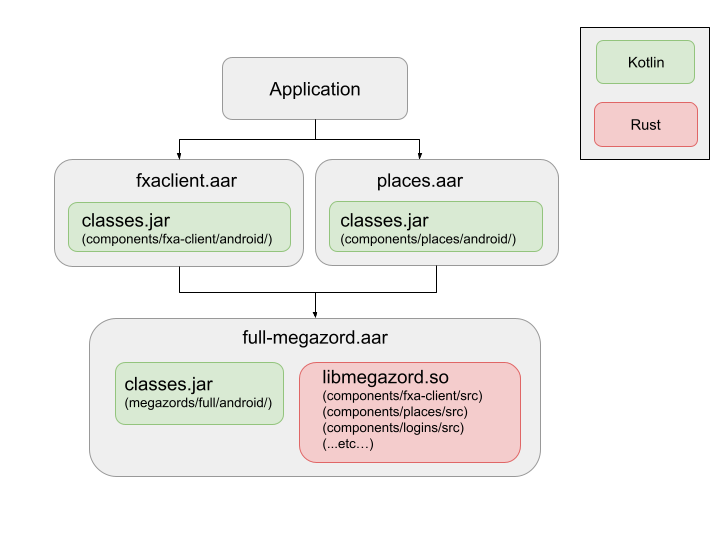
简单来说,就是有个 Rust 的壳工程作为唯一生成二进制的 crate,其他组件如 autofill, logins, sync_manager 作为壳工程的依赖,把 udl 文件统一生成到一个路径,最终统一生成绑定文件和二进制。好处是避免了多个 rust crate 之间的调用消耗,只生成一个二进制文件,编译发布集成会更容易。
安卓平台:是生成一个 aar 的包,Mozilla 团队提供了一个 org.mozilla.rust-android-gradle.rust-android 的 gradle 插件,可以在 Mozilla 找到具体使用。
苹果平台:是一个 xcframework,Mozilla 的团队提供了一个 build-xcframework.sh 的脚本,可以在 Mozilla 找到具体的使用。
我们只需要适当的修改下,就可以创建出自己的跨平台的项目。
实际上我们使用 uniffi-rs Mozilla 的项目还是比较复杂的,这里你可以使用 mobile sdk 来学习如何打造自己的跨平台组件:
这里大家也可以参考 Github Actions 编译和构建。
